
Wer schreibt das Protokoll?
Während es in den alten Mad Men-Zeiten keine Frage war, dass eine Sekretärin möglichst unauffällig das Geschehen dokumentierte, ist die Frage nach dem Protokoll in unseren ach so modernen Zeiten scheinbar komplett aus der Mode gekommen. Gerade jetzt, wo wir unbegrenzt Speicherplatz haben, wo Intranet-Suche jeden Info-Schnipsel innerhalb einer Sekunde aufspüren könnte, gibt es von den allermeisten Meetings keinerlei zentrale Aufzeichnungen. Irgendwie eigenartig, finden Sie nicht? „The Big Three“ der Collaboration-Lösungen, also Cisco Webex, Microsoft Teams und Zoom überbieten sich aktuell, mittels innovativer Technik die Zusammenarbeit nachhaltig zu verändern. Der neueste Streich sind die sogenannten Intelligent Speakers für Microsoft Teams. Diese sind nun sehr bald (ca. Juni 2021) verfügbar, nachdem die offizelle Ankündigung zur Ignite im September 2020 kam. Kennern der Szene war das aber schon seit ca. Sommer 2018 bekannt, als Microsoft erstmals auch außerhalb der eigenen Reihen darüber sprach.
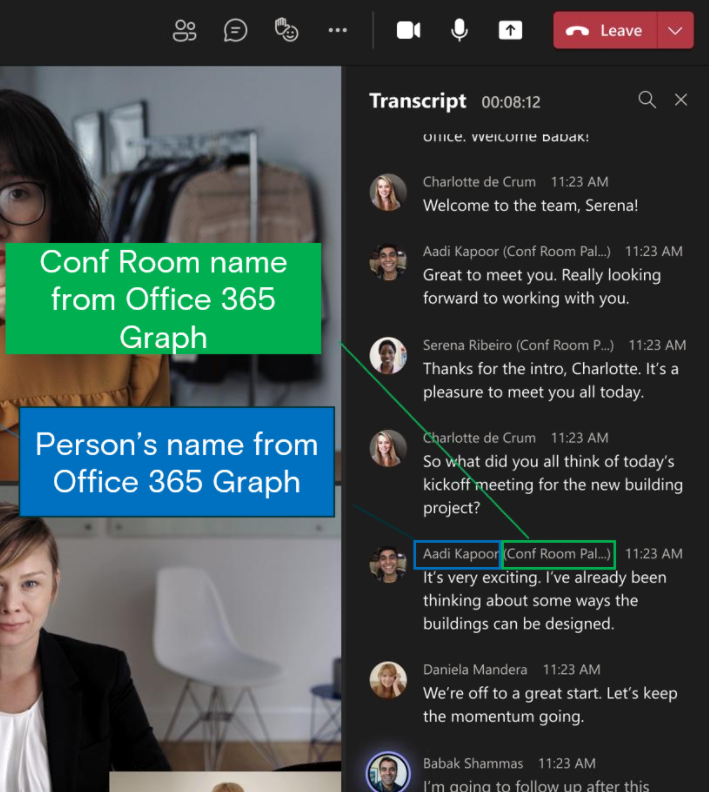
Zur Erinnerung: Real Time Transcriptions gibt es bereits in MS Teams, funktioniert aber nur dann, wenn alle Teilnehmer schön brav einzeln mit dem eigenen Client teilnehmen. MS Teams „erkennt“ die Teilnehmer dann nicht anhand Ihrer Stimme, sondern an Ihrem MS Teams Account. Das funktioniert natürlich nicht, wenn eine Gruppe Personen in einem Meetingraum sitzt und das Meeting im Kontext des MTR läuft.
Meeting-Dokumentation. Was, wie und warum?
Emails und Chat-Messages leben quasi ewig und in vielen Unternehmen MÜSSEN diese sogar viele Jahre archiviert werden. Aber was ist mit Meetings? Was dort gesprochen, jedoch mangels Sekretärin nicht mehr in Schriftform transkribiert wird, ist flüchtig wie eine Instagram Timeline. Der RECORD-Button der Collaboration-Plattform hilft nicht wirklich, weil Audio/Video-Files nicht leicht durchsuchbar sind. Neben dem WAS ist selbstverständlich auch das „WER hat’s gesagt“ ebenfalls wichtig.
Folglich ergibt sich ein klares Pflichtenheft für das Thema Meeting-Protokoll:
- Sprachdokumentation aller Teilnehmer, egal ob im Raum oder per remote, jeder mit seinem persönlichen Device oder in einer Gruppe
- Speech to Text, also die Transkription (=Verschriftlichung) der einzelnen Wortmeldungen.
- Sprecher-Erkennung = Zuordnung der Wortmeldungen zu den Teilnehmern.
- Hinzufügen von Meta-Informationen wie Datum, Zeit, Ort, Kontext, u.ä.
Hier zählt auch der Kontext zwischen Text und der entsprechenden Stelle in der Videoaufzeichnung dazu. (Link für Neugierige: VTT = Video Text Tracks ).
Optional, aber wenn man sich schon die Mühe macht:
- LIVE-Untertitel zum Mitlesen. Diese helfen besonders, wenn Sprecher und/oder Zuhörer eine Fremdsprache sprechen/hören müssen.
Praxistipp: Wer verspätet zu einem Meeting dazustößt, kann kurz nachlesen, was bisher geschah. - LIVE-Übersetzung: Wenn der Text nun schon in Real-Time erkannt wird, kann er natürlich auch gleich live übersetzt werden. Jedem seine eigenen Untertitel! Der Schritt zum nochmaligen Text-To-Speech, also die Übersetzung in andere GESPROCHENE Sprache, ist dann nicht mehr allzu weit!
- Zusatzinfos bzw. Kontext-Erweiterung: Wir alle kennen das: Arbeitsgruppen sprechen intern immer in Abkürzungen oder geben Ihren Projekten & Features Spitznamen. Ein schlaues System erkennt dies und ersetzt dies automatisch mit den richtigen Begriffen.
- Intelligente Links: Wie wäre es, wenn im Protokoll automtisch ein Link eingefügt wird, wenn jemand „wie wir letzten Mittoch im Marketing-Meeting besprochen haben…“ sagt? Noch ist das Zukunftsmusik, aber wie lange noch?
- Praktisch alle Anbieter arbeiten daran, aus der Spracherkennung konkretes Real-Time-Feedback an die Sprecher zu liefern:
Ob aber Text-Einblendungen wie z.B. „Sprechen Sie langsamer“ oder „Sie klingen sehr nervös“ wirklich hilfreich sind, darf hinterfragt werden.
Sprach- versus Sprecher-Erkennung
Wie geht Microsoft das Thema nun konkret an? Dass nichts ohne Cloud-Power geht, war zu erwarten und muss nicht extra erwähnt werden. Thematisch passt das Ganze zur CORTANA-Technik von Microsoft, verwendet also die entsprechenden AZURE-Cognitive-Services-Dienste.
Dieser Cloud-Dienst lernt permanent dazu, folglich unterstützt Cortana auch laufend zusätzliche Sprachen, Dialekte sowie Fachausdrücke.
Für einzelne Teilnehmer eines MS Teams Calls ist die Sprecher-Erkennung nicht allzu schwer, weil MS Teams davon ausgeht, dass ein User unter seinem eigenen Account arbeitet (siehe oben).
Was aber machen wir mit den 5 Leuten, die gemeinsam im Meetingraum sitzen? Die kein Headset mit 3cm Besprechungsabstand benutzen, sondern ein MTR in einem halligen Glas-Aquarium verwenden? Genau hier wird es spannend! Hier ist die SPRECHER(innen)-Erkennung alles andere als banal.
Microsoft löst dies auf folgende Weise:
Im Microsoft Teams Desktop-Client bekommt der User die Möglichkeit per Teams Voice Recognition seine eigene Voice ID aufzunehmen. Man liest dem System dazu einen eingeblendeten Text vor; dies soll max. 30 Sekunden dauern. Die Sprachaufnahme wird in der Cloud analysiert und ein Voice-Print zum M365 Konto hinzugefügt. Neben Namen, Profilbild und Ähnlichem nun also auch noch ein weltweit einzigartiger biometrischer „Sprachabdruck“. Dieser ist logischerweise so lange gespeichert, wie der User ein M365 Konto hat. Warum aber der VoicePrint danach (!) noch weitere 3 Jahre gespeichert bleibt, ergibt natürlich Stoff für wichtige Diskussionen. Ja, diese Aussage stammt direkt von einem Microsoft Mitarbeiter!
Noch ein Device mehr am Tisch?
Nachdem MS Teams nun alle Benutzer an der Stimme erkennt, wenden wir uns der Praxis zu.
Im TAC (Teams Administration Center) stehen nun zusätzliche Policies and Konfigurationen zur Auswahl. Darf der Meeting-Organisation die Funktion je Meeting aktivieren oder deaktivieren? In welchen Räumen ist es per default ON oder OFF, usw.
Man kennt das; Microsoft denkt hier immer sehr umfangreich. Auch vollkommen anonyme Meetings sind möglich (na Gott sei Dank!). Die Sprecher heißen dann nur User1, User2, usw…
Sie werden also weiterhin erkannt und getrennt protokolliert, nur nicht mit ihrem richtigen Namen. Hmm, volle Anonymität sieht anders aus, liebe Microsoft!
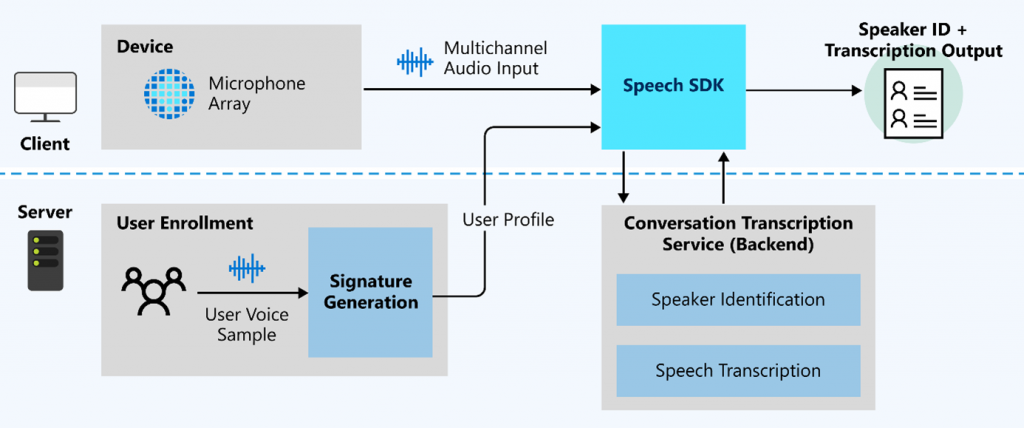
Im Meetingraum selbst werden aber nicht die vorhandenen Mikrofone und Lautsprecher verwendet, sondern eine eigene Hardware mit dem Kategorienamen Intelligent Speakers für Microsoft Teams. Diese darf man sich als Business-Version einer Amazon ALEXA Box vorstellen. Die ersten Hardware-Partner sind EPOS (entstanden aus der ehemaligen Sennheiser Communication) und YEALINK, die offenbar bei jeder Microsoft Teams Kategorie unbedingt dabei sein muss.

Über die Hardware ist nicht viel bekannt außer dass Mikrofon-Arrays eine große Rolle spielen. Das ist auch verständlich, denn die Richtung, aus der eine Stimme kommt, ist eine essenzielle Information, wer denn gerade spricht! Dies ist auch der Grund, warum es (zumindest bis dato) nicht über bestehende Mikrofone funktioniert. Man muss kein Hellseher sein, um vorauszusagen, dass Mikrofon-Arrays, Beamtracking & Co in kommenden MTR-Generationen eine wichtige Rolle spielen werden! ?
Bis dahin benötigt man diese spezielle Hardware. Die Arbeitsteilung zwischen dem Device und der Cloud ist nicht bekannt; also wieviel Intelligenz in der Box am Tisch und wieviel in der Azure Cloud passiert. Man darf aber vermuten, dass die Cloud-Seite volle Kontrolle über die Hardware am Tisch hat.
Cortana Fernbedienung
Liegt nun schon ein Cortana-fähiges Device auf dem Tisch, könnte es dann nicht gleich die Sprachsteuerung des MTRs übernehmen? JA, das kann es und man wird schon bald in vielen Meetingräumen „Cortana, join the meeting“ oder „Cortana, hole Max Mustermann zu diesem Meeting“ hören.
Persönliche Anmerkung des Autors:
Ich gebe es zu; der Verzicht auf jegliche Form von Bitte und Danke bei Alexa, Siri und Co nervt mich gewaltig!
Harald Steindl
Und nach dem Meeting?
Die Transkription steht nach dem Meeting wie schon bisher die Video-Aufnahme im Kontext des Teams zur Verfügung. Folglich wird die Teams-eigene Suche auf das Protokoll zugreifen können oder je nach Einstellung auch Intranet-Dienste wie Sharepoint & Co.
Interessant sind zwei konkret angekündigte Features für kommende Versionen:
- Sprach-Erkennungs-Nachhilfe
Wenn sich die Sprecher-Erkennung nicht sicher ist, Beiträge mit „Sprecher 1“ statt mit Namen angezeigt. Natürlich darf es auch „Sprecher 2“ usw. geben, denn unterschiedliche Sprecher kann das System viel leichter erkennen als die konkrete Zuschreibung zu einer bestimmten Person. Spannend ist nun die Möglichkeit der nachträglichen Editierung. „Sprecher x“ Schnipsel können manuell den richtigen Identitäten zugeordnet werden.
Wir dürfen uns alle sicher sein, dass im Hintergrund diese Info auch an die Cloud geht und das System so mit der Zeit immer besser funktioniert bzw. die VoiceIDs verfeinert!
Diese Technik ist altbekannt. - Vielen Branchen werden nicht nur Abkürzungen, sondern auch spezielle Termini, die Außenstehenden wie eine eigene Sprache vorkommt. Nicht nur uns geht es so, auch MS Azure stellt das vor schwer lösbare Herausforderungen.
Organisationen können dem System (und somit sich selbst!) künftig helfen, indem sie eigene Wörterbücher samt Sprach-Samples auf die M365 Plattform hochladen. Man definiert eigene Transkriptions-Regeln, ob z.B. Abkürzungen automatisch voll ausgeschrieben ins Protokoll übernommen werden. Mit Sicherheit interessant für Mediziner, Juristen und Technologie-Unternehmen.
Daraus stellt sich die interessante Frage, wie weit sich das Protokoll vom tatsächlich gesprochenen Wort entfernen darf. Werden „Kraftausdrücke“ fein säuberlich verschriftlicht oder in bester Comic-Manier durch „§$%&“ ersetzt?
Preis und Verfügbarkeit
Intelligent Speakers für Microsoft Teams sind Stand heute (April 2021) ab ca. Juni 2021 verfügbar. EPOS nennt für sein Produkt EXPAND Capture 5 einen Listenpreis von EUR 419,- exkl. MWSt. Eigentlich gar nicht so teuer, wenn man bedenkt, welchen LANGFRISTIGEN Wert es damit stiftet. Von Microsoft Seite gibt es keinerlei Preisinformation zu diesem Dienst. Dürfen wir daher davon ausgehen, dass dieses Feature mit der normalen MS Teams Lizenz abgedeckt ist? Ich bin mir da nicht so ganz sicher, denn Sie erinnern sich noch meinen Artikel zum Thema Advanced Communication Lizenz?
Aktuell funktionieren die Intelligent Speakers für Microsoft Teams nur mit MTRoW, also dem Teams Room System auf WINDOWS Basis. Der Grund ist einfach erklärt: Das EXPAND Capture 5 hat neben dem Mikrofon-Array auch einen eingebauten Lautsprecher. Per USB an den MTR-Rechner angeschlossen und das Audio-Thema ist (zumindest für kleinere Räume) damit gleich erledigt.
Ausblick für Intelligent Speakers für Microsoft Teams
Microsoft verwendet im Zusammenhang mit Intelligent Speakers für Microsoft Teams folgende Buzzwords: Intelligent transcription, speaker attribution, speech recognition, touchless remote control, inclusive meetings powered by Microsoft Teams. Sehr interessant auch der offizielle Titel des Projektleiters bei Microsoft hinter diesem Projekt: „Senior Director of Teams Intelligent & Ambient Experiences“ und die Definition seiner Aufgabe als „using cutting edge technologies such as computer vision, speech interpretation, artificial intelligence & machine learning”. Man darf also gespannt sein, welche Innovationen hier noch auf die MS Teams User zukommen werden. Ich habe da schon so meine Ideen, wohin die Reise gehen wird. Microsoft wäre nicht Microsoft, wenn man nicht permanent scheinbar nicht zusammenhängende EInzelprojekte immer und immer wieder in das bestehende M365 Universum einweben würde.
Damit stegt ie Eintrittshürde für etwaige Mitbewerber immer weiter. Man muss es einmal klar aussprechen: Was Microsoft, Cisco und Zoom mittlerweile alles in Ihre Plattformen inkludieren, hätte NIEMAND vor 3 Jahren auch nur zu ahnen gewagt.
Eines steht für mich fest:
Persönliche Notizen wird es auch weiterhin geben aber das offizielle Meeting Protokoll scheint gerade ein großes Comeback zu feiern. Wird das Ganze dann noch in eine zentrale Data-Governance Strategie eingebunden, die Daten also vernünftig verwaltet und aktiv genutzt, dann erhalten Unternehmen einen echten Produktivitätsgewinn.
Auf die dunkle Seite der Technologie wie cloud-gespeicherter Voice-ID = akustischer Fingerabdruck sowie Gesichtserkennung im Videocall dürfen wir jedoch nicht vergessen. Hier ergeben sich ganz neue Fragen in Sachen Datenschutz & Co.
Was sagen Sie dazu? Ich freue mich auf Ihr Feedback!
5 Gedanken zu „Intelligent Speakers für Microsoft Teams“
Die Kommentare sind geschlossen.